MÓDSZERTANI MEGJEGYZÉSEK
a 2016. évi egyéni bér-kereset adatfelvételekhez
és eredményeik értékeléséhez
Az érdekegyeztetéshez szükséges adatok biztosítására kialakított egyéni bér- és kereset felvétel 2016-ben is az előző években bevezetett adatgyűjtési módszerrel került lebonyolításra. A vállalkozói és a költségvetési szférában gyakorlatilag azonos volt az adatfelvétel tartalma és vonatkoztatási időszaka (május hó), a kereset összetevők fogalmaiban használatos eltérések miatt azonban célszerű volt külön adatlapot és kitöltési útmutatót készíteni a két kör számára.
I. AZ ADATFELVÉTEL FŐBB JELLEMZŐI
A költségvetési intézményekben
foglalkoztatottak adatfelvétele a helyi költségvetésről teljes körű volt, mind
az intézmények, mind az ott dolgozó teljes munkaidős munkavállalók
tekintetében.
Az adatfelvételt a központi bérszámfejtési rendszeren keresztül bonyolítottuk
le, illetve a számfejtési körükből kivált intézményektől, valamint a központi
költségvetési szervezetek központi bérszámfejtési körén kívüli intézményektől
közvetlenül kértük az adatszolgáltatást, reprezentatív módon, mintegy 9 %-os
minta kiválasztásával.
A vállalkozói szférában, valamint a non-profit szervezeteknél ez évben 2 főnél többet foglalkoztató vállalkozásoknál került sor reprezentatív adatfelvételre.
Az 50 főnél többet foglalkoztató vállalkozásoknál a kiválasztás előírásainak figyelembe vételével a mintába a fizikai dolgozók kb. 6 %-a, a szellemi foglalkozásúak mintegy 9 %-a került be.
Az 2-50 fő közöttieknél a szervezetek közül választottunk 20 %-os mintát, az így bekerült vállalkozásoknak viszont minden teljes munkaidős dolgozójukról kellett adatot szolgáltatniuk.
A vállalkozói szférában és a költségvetés azon részében, ahol reprezentatív mintavétellel teljesítették az adatszolgáltatást - a mintavételi arányok alkalmazásával, statisztikai módszerekkel - teljeskörűsítve lettek az adatok, ami a minta alapján a reprezentált teljes sokaságra való következtetést jelenti. Ez a következtetés - statisztikai szakkifejezéssel a teljeskörűsítés - az egyénekhez rendelt súlyokkal (a mintavételi arány reciprokával) való felszorzás útján történik.
Ha valakihez például 5 %-os mintavételi arány alapján 1/0,05=20 szorzó tartozik, ez azt jelenti, hogy ez az ember a teljes sokaságból 20 főt képvisel, hasonlóképpen 8,25 %-os minta 12-es súlyt eredményez.
A súlyszámok meghatározása gyakorlatilag úgy történik, hogy a szervezetnél dolgozó összes teljes munkaidőben foglalkoztatott dolgozók számát elosztjuk a mintába bekerültek számával. Ez azt jelenti, hogy a közlési táblákban található adatok statisztikai számítások eredményei, amelyek a teljes reprezentált (rész)sokaságokra így kapott értékeket mutatják be, vagyis a minta alapján az egész reprezentált sokaságra és különböző bontásaira vonatkozó becsléseknek tekinthetők.
A becslések pontossága, megbízhatósága annál jobb, minél nagyobb részsokaságra készülnek és annál kevésbé jó, minél kisebbre. Ennek következménye, hogy a reprezentatív adatfelvételből készülő feldolgozások esetében - a különböző bontásokat tekintve - célszerű önmérsékletet tanúsítani, illetve, ha az egyes becslések megbízhatósága meghatározott szint alá süllyed, a szóban forgó adatokat célszerű külön jelzéssel ellátni, vagy - mint nem értékelhetőket - nem is célszerű közölni (lásd még a becsült adatok pontosságáról szóló részben).
Megfeleltetett és nem megfeleltetett foglalkoztatottak
Az adattár számos táblájának bontása illetve a grafikonok adatai az úgynevezett megfeleltetett foglalkoztatottak körére vonatkoznak.
Kik a megfeleltetett foglalkoztatottak?
Az egyéni bérek és keresetek adatfelvétel egyik különlegessége, hogy a költségvetésben foglalkoztatottak munkaköri csoportjait a versenyszférában foglalkoztatottak hasonló munkaköri csoportjához illeszti és kiszámítja a megfeleltetett munkakörök bér- és kereset átlagának arányát, az un. összehasonlító indexet.
A versenyszférában minden alkalmazásban álló megfeleltetett, a közfoglalkoztatottak azonban nem. A költségvetésben dolgozók közül nem mindem alkalmazottat lehet megfeleltetni; vannak olyan munkavállalók, akiknek annyira egyedi a munkakörük, hogy nem lehet a versenyszféra foglalkoztatottjainak megfeleltetni őket (pl. választott tisztségviselők, egyetemi tanárok, katonák stb.), illetve a közfoglalkoztatottakat sem feleltetjük meg. Így a költségvetésben jóval magasabb a nem megfeleltetettek aránya az össz foglalkoztatottakon belül, mint a versenyszférában.
A nemzetgazdaságban - a költségvetési szektor miatt - szintén magasabb a nem megfeleltetettek aránya, mint a versenyszférában.
A megfeleltetést az un. munkaköri besorolási rendszer segítségével végezzük el. A költségvetésben dolgozók kulcsszámait (minden költségvetésben munkát vállalónak van egy kulcsszáma, amely alapján számítják az illetményét) a versenyszférában dolgozók (a 6/1992-es MüM rendeletben meghatározott) munkaköri besorolási kódszámának feleltetjük meg.
A megfeleltetés célja, hogy pontos képet kapjunk a versenyszféra és a költségvetés kereset különbségeiről. A két szektor abszolút kereset átlagainak összehasonlítása ugyanis torzít, amiatt, hogy a költségvetés és a versenyszféra foglalkoztatottjainak összetétele különböző, a költségvetésben pl. sokkal magasabb az egyetemi végzettséggel rendelkezők aránya. Az összehasonlító index az összetétel különbözőségét kiküszöböli, és így mutatja az egyes bontásokban a két szektor közötti bér- és kereset különbségeket.
II. A TÁBLÁZATOKBAN TALÁLHATÓ FOGALMAK MAGYARÁZATA, AZ EGYES ADATOK (BECSLÉSEK) SZÁMÍTÁSI MÓDSZEREI
1./ Létszám:
Közölt létszám: a táblázat adott sorába bekerült minta-elemek létszámsúlyainak összege, vagyis a sor átlagos létszámsúlya szorozva az adott sor mintalét-számával. ( A közölt létszám nem azonos az adott aggregátumban ténylegesen foglalkoztatottak létszámával, hanem azt fejezi ki, hogy a bér- és kereseti adatok mekkora létszámra vonatkoztathatók.)
2./ Személyi alapbér:
Az adott hónapra vonatkozó
o Vállalkozásoknál, a közigazgatásban a Munka Törvénykönyve hatálya alá tartozóknál és a nem profitorientált szervezeteknél: a munkavállalónak a munkaszerződésben meghatározott személyi alapbére hónapra meghatározva.
Órabér esetén a havi alapbér megállapítása az évben átlagosnak tekinthető 173,8 havi fizetett óraszám figyelembe vételével történik.
o Közalkalmazottaknál: az illetmény (ami magába foglalja a szakmai szorzó miatti, valamint a további szakképesítésért járó illetményrészt, valamint a munkáltató döntése alapján biztosított illetményrészt és a pedagógusoknál a kötelező óraszám emelése miatt végrehajtott illetményemelést)
o Köztisztviselőknél: az alapilletmény, az illetménykiegészítés és a vezetői pótlék együttes összege.
o Kormánytisztviselőknél: az alapilletmény, az illetménykiegészítés és a vezetői pótlék együttes összege.
o Bírák és ügyészeknél: az alapilletmény, a beosztási-, valamint a vezetői pótlék együttes összege.
o A hivatásos állományúaknál (akiknek az adatai csak összevontan, az összehasonlító indexek számítása során figyelembe nem vettként szerepelnek) a beosztási illetmény, az illetménykiegészítés, a rendfokozati illetmény (pótlék) és a vezetői pótlék együttes összege.
Az egyes soroknál az oda tartozó minta-elemek megfelelő adatainak az egyénenkénti létszámsúlyokkal számított súlyozott számtani átlaga jelenik meg.
3./ Teljes kereset:
A megfigyelt hónapban számfejtett összes bruttó kereset, melyhez hozzáadjuk az előző évi nem havi rendszerességű prémiumok, jutalmak, 13. havi fizetés 1/12-ed részét. Az egyes soroknál itt is a fentiek szerint számított súlyozott számtani átlag jelenik meg.
4./ Relatív szórás:
A szórás és az átlag aránya százalékban kifejezve.
Szórás = az egyes ismérv értékek és a számtani átlag közötti különbségek négyzetes átlaga (létszámsúlyokkal számítva).
5./ Relatív helyzet index:
· a nemzetgazdaság átlagához viszonyított nagyság %-ban, a nemzetgazdasági szintű feldolgozásokban,
· a vállalkozások átlagához viszonyított nagyság %-ban, a vállalkozói szféráról készült feldolgozásokban,
· a költségvetés átlagához viszonyított nagyság %-ban, a költségvetési szféráról készült feldolgozásokban,
· a meghatározott aggregátum átlagához viszonyított nagyság %-ban, azokban a feldolgozásokban, ahol kifejezetten a kiválasztott körön belüli - egy ágazatba tartozók,
egy rendelet alá tartozók, stb. - viszonyokat kívánjuk bemutatni.
6./ Összehasonlító bér- és kereset indexek:
Az adott metszetben (pl. ágazat, foglalkozás, nem, korcsoport) fizetett tényleges átlagos bérek, illetve keresetek, és a versenyszféra besorolási kategóriánkénti országos átlagaival számított bérek, ill. keresetek hányadosa, ahol természetesen mindkét átlag a kategóriánkénti létszámokkal súlyozva kerül meghatározásra. Ez a hányados adja az összehasonlító bér- ill. kereset indexet, százalékban kifejezve.
Ezek az indexek azt fejezik ki, hogy az adott metszetbe tartozóknak - a létszámsúlyaikkal számított - tényleges átlagos besorolási bére (illetménye), illetve teljes keresete %-ban kifejezve mekkora ahhoz a bér- és keresetátlaghoz képest, amelyet úgy kapunk, hogy ugyanezen létszámsúlyokkal a bér-kategóriánkénti (versenyszférára - tehát a vállalkozói körre - vonatkozó) országos átlagokkal számítjuk ki a megfelelő adat átlagát.
Másképpen fogalmazva azt fejezik ki ezek az indexek, hogy átlagosan mennyit kapnak az adott metszetbe tartozó emberek ténylegesen ahhoz képest, amekkorára az átlagaik akkor adódnának, ha minden egyes ember pontosan annak a bérkategóriának a versenyszférabeli országos átlagát kapná, amelybe beletartozik (illetve, amelynek a besorolása megfeleltethető). Ha az index a 100 %-ot meghaladja, akkor ez az adott metszetre előnyt, 100 % alatti érték pedig elmaradást jelez.
7./ Az adatok nem közölhetők
- felírat található minden olyan adatsorban, ahol az adatszolgáltatók száma háromnál kevesebb.
III. A BECSLÉSEK PONTOSSÁGA
Ismeretes, hogy a táblázatainkban szereplő adatok (a helyi költségvetés kivételével) nem teljes körű felvételből származnak, hanem az adatszolgáltatáshoz előírtak szerint kiválasztott reprezentatív mintán alapulnak. Ily módon ki vannak téve a mintavétel miatti véletlenszerű eltéréseknek. Az így kapott becslések tehát kisebb-nagyobb mértékben eltérhetnek azoktól az adatoktól, amelyeket egy teljes körű felvétel esetén nyerhettünk volna. Ez a különbség, amelyet "mintavételi hibának" nevezünk, nem tévesztendő össze az adatok pontatlanságával, ami származhat akár a szolgáltatott adatok nem tökéletes voltából, akár az adatfeldolgozás hibáiból. Ez utóbbi pontatlanságot nevezzük "nem mintavételi hibának", ami bármely statisztikánál előfordulhat, akár teljes körű, akár mintavételes az adatgyűjtés. Ez utóbbi hibalehetőséget sokoldalú ellenőrzéssel és a szükségszerű javításokkal igyekeztünk minimálisra csökkenteni.
A mintavételi hiba nagyságát az un. "standard hiba" mértékével, ill. ennek az átlag %-ában kifejezett relatív nagyságával lehet jellemezni. Táblázatainkban minden átlagot és szórást jelzés nélkül kimutattunk, ahol a standard hiba nem haladta meg a minta átlagának 10 %-át. Közöljük azokat az adatokat is, ahol a relatív standard hiba 10 és 20 % közé esett, de ezeket a sorokat csillag (*) jelzéssel láttuk el. 20 % felett "nem értékelhető" megjegyzést tettünk, és az adatokat nem nyomtattuk ki. (Megjegyezzük, hogy az adatok túlnyomó többségénél a relatív standard hiba 8 % alatt van.)
A standard hiba mértéke az alábbi tényezőktől függ:
- a minta nagysága (minta létszám), jele: n
- a teljes sokaság (közölt létszám), jele: N
- a mintából becsült szórás, jele: s
Ezen tényezőkkel a standard hiba (SH) a következő képlet segítségével számítható ki:
![]()
a relatív standard hiba (RSH) pedig (a standard hiba az átlag %-ában a következő képlettel határozható meg:
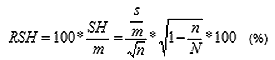
ahol "m" a minta átlagát jelenti.
Ha a teljes sokaság nagyságát (N) és a minta relatív szórását (s/m) rögzítjük, akkor független változóként az n/N hányadost alkalmazhatjuk.
Ha a minta-arány n/N = x, akkor n = x*N és a relatív standard hibát a következők szerint határozhatjuk meg:
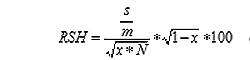
A standard hiba, illetve a relatív standard hiba azt fejezi ki, hogy a minta átlagától a valóságos átlag 68,3 %-os valószínűséggel ekkora "távolságon" belül van.
Annak valószínűsége, hogy a "valóságos" átlag és a mintából kapott becslés közötti különbség belül van a standard hiba (illetve a relatív standard hiba) kétszeresével számított távolságon, már 95,5 %. Háromszoros standard hibán belül van ez a távolság 99,7 %-os valószínűséggel.